1. Background
➜ AWS Batch는 AWS의 클라우드 기반 서비스 중 하나로, 대규모의 계산 작업을 쉽게 처리할 수 있는 관리형 서비스
➜ 이 서비스를 사용하면 컴퓨팅 자원을 효율적으로 활용하여 대규모 작업을 분산 처리할 수 있음
➜ 배치 작업을 편리하게 할 수 있는 서비스
➜ 작동 원리

✅ 작업을 특정 작업 대기열에 제출하면, 작업은 컴퓨팅 환경에 스케줄링될 때까지 해당 대기열에 남아 있음, 작업 대기열에 연결된 컴퓨팅 환경과 작업 대기열 자체에 우선순위 값을 할당 가능
✅ 작업 정의에서 지정한 매개변수를 사용하여 AWS Fargate 또는 Amazon EC2 리소스에서 컨테이너화된 애플리케이션으로 작업을 실행
✅ 실행 중인 작업의 상태를 모니터링하고 완료된 작업의 결과를 보고, AWS batch 콘솔에서 최근 작업/작업 대기열 및 컴퓨팅 환경을 확인할 수 있음
✅ 작업은 다른 작업의 이름이나 ID를 참조하고, 다른 작업의 성공적인 완료에 의존 가능
2. ubuntu
➜ aws, docker 설치 확인
➜ aws configure로 접속
3. 실습
➜ AWS Amazon Elastic Container Registry 접속
✅ 생성 (모두 default 값) : 970547362503.dkr.ecr.ap-northeast-2.amazonaws.com/shinjuhee-repo [url]
✅ 아래 명령 Linux에 복붙

✅ nano simple_math_batch_job.py
# simple_math_batch_job.py
import math
# 파이 값(π)을 소수점 10자리까지 계산
pi_value = round(math.pi, 10)
# 결과 출력
print(f"Calculated value of Pi to 10 decimal places: {pi_value}")
✅ nano Dockerfile
FROM python:3.8-slim
WORKDIR /app
COPY simple_math_batch_job.py /app/
CMD ["python", "simple_math_batch_job.py"]
➜ 이미지 올라간 것 확인

➜ 컴퓨팅 자원 생성
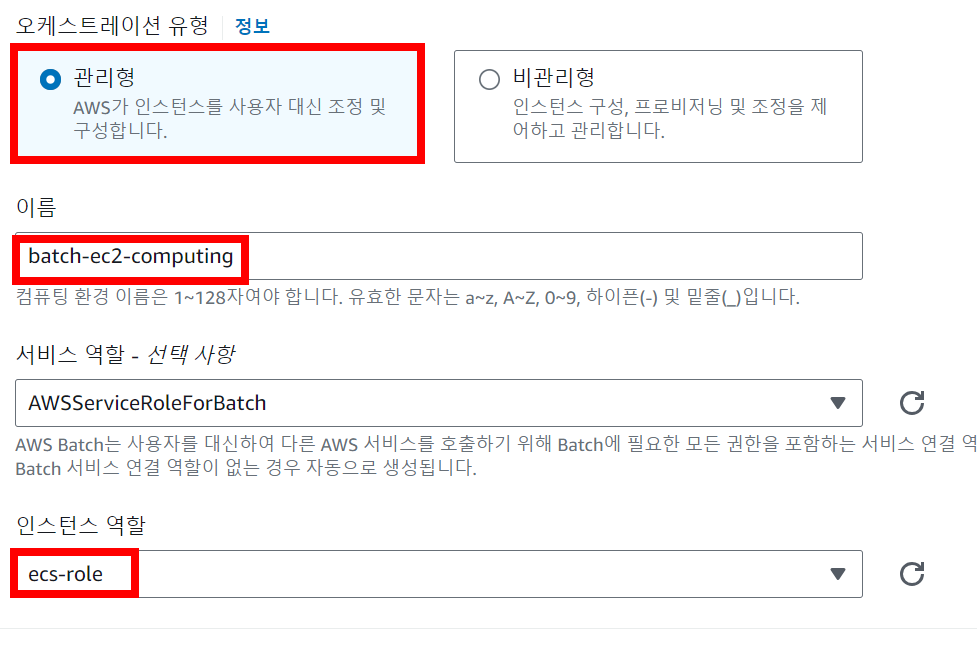
✅ 컴퓨팅 환경 > 생성 > EC2 > 관리형 > 이름 [batch-ec2-computing] > 인스턴스 역할 생성 [IAM > role > EC2 > AmazonEC2ContainerServiceforEC2Role 권한 선택 > 이름 주기 [ecs-role]
✅ 비용 절감을 위해 스팟 인스턴스 사용을 활성화 : 옵션들은 default, 추가 구성 [ 할당 전략 정보 : Spot capacity optimized ]
✅ 배치만 관리하는 거라 EC2에 나타나진 않음
➜ 작업 정의
✅ 생성 : EC2 > 이름 : batch-job-definition99 > 실행 시간 : 60
✅ 컨테이너 구성 : 위의 ECR image url 복붙하여 이미지에 넣기

➜ 대기열 생성
✅ 생성 : EC2 > 이름 : batch-job-queue999 > 연결된 컴퓨팅 환경 : batch-ec2-computing

➜ 작업 생성
✅ 새 작업 제출 > 이름 : job-test-by-shin-0905 > 작업 정의 : batch-job-definition99 > 작업 대기열 : batch-job-queue999
✅ 컨테이너 재정의 : ["python", "simple_math_batch_job.py"]

➜ 대시보드에서 Succeed 된 것 확인

➜ 로그 스트림 이름 > Cloudwatch로 넘어감 > 확인

3. AWS athena, glue
➜ AWS glue
✅ amazon web services의 일부로 이벤트 중심의 서버리스 컴퓨팅 플랫폼\
✅ 분석 사용자가 여러 소스의 데이터를 쉽게 검색, 준비, 이동, 통합할 수 있도록 하는 서버리스 데이터 통합 서비스 ✅ 간단하게 여러 데이터 스토어 및 스트림 간에 원하는 데이터를 분류, 정리, 보강, 이동
✅ 서버리스이므로 설정하거나 관리할 인프라가 없음
➜ AWS athena
✅ 표준 SQL을 사용하여 Amazon S3에 있는 데이터를 직접 간편하게 분석할 수 있는 대화형 쿼리 서비스
➜ 버킷 만들기 (데이터가 저장될 곳) > 이름 : shinjuhee0906, 나머지는 default > 파일 업로드 [ inventory.csv ] > IAM ROLE : AWSGlueServiceRole-crawler-role > Set output and scheduling : Create a database : aws-crawler-db > 새로고침하여 db 추가 > Crawler schedule : on demand > Run crawler
➜ 버킷 만들기 (쿼리가 저장될 곳) > 이름 : athena-output-storage-0906
➜ Amazon Athena > 작업 그룹 생성 > 이름 : athena-0906, 쿼리 결과 구성 : 생성한 S3 선택 (무조건 뒤에 / 추가하기) > 쿼리당 데이터 사용량 컨트롤 : 10GB
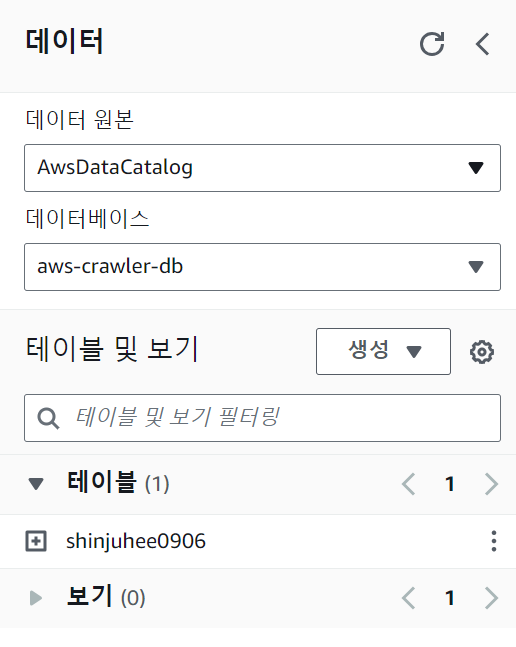
➜ 쿼리 편집기 [ 작업 그룹 위에서 생성한 것으로 선택 ] > 생성 > set crawler properties > 이름 : aws-glue-crawler > Add data source [ S3, browse : S3 연결 (s3://shinjuhee0906/) ]

✅ 자동으로 세팅된 데이터 확인
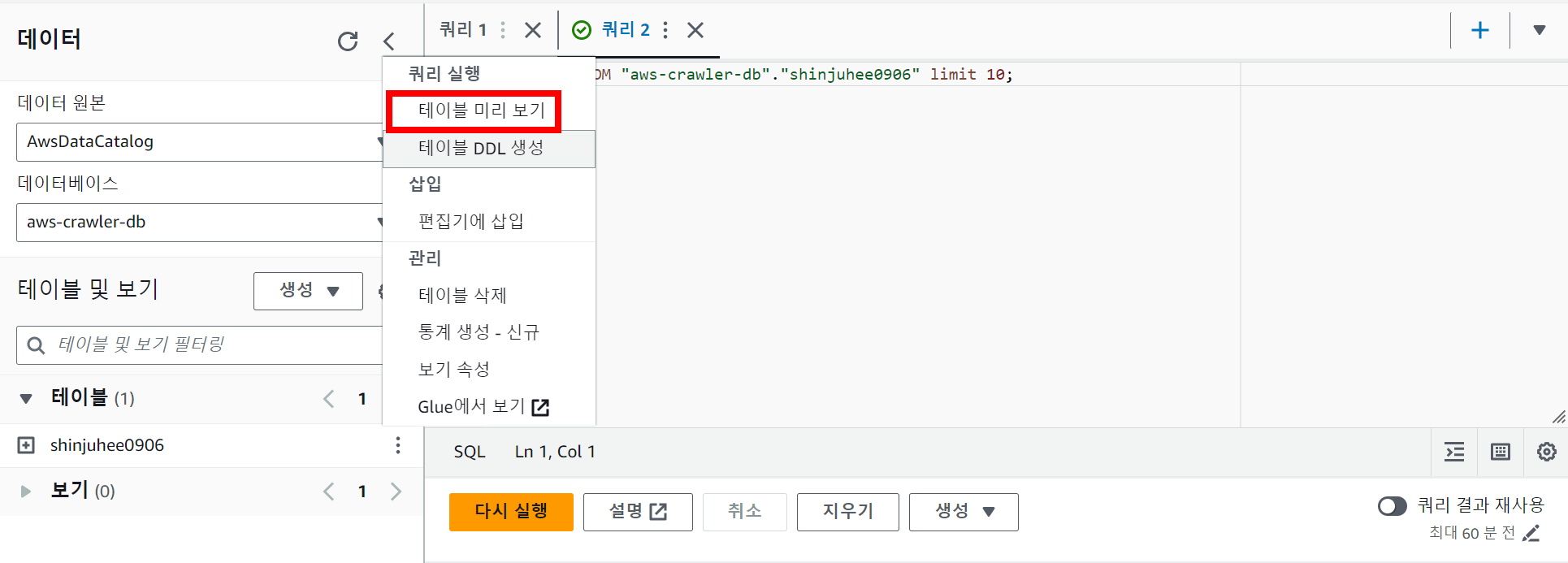
✅ 테이블 미리 보기
➜ 버킷에 폴더 Inventory 생성
✅ 파일 다 올리기 (excel 파일) : 폴더 하나에 자료 하나씩 만들기
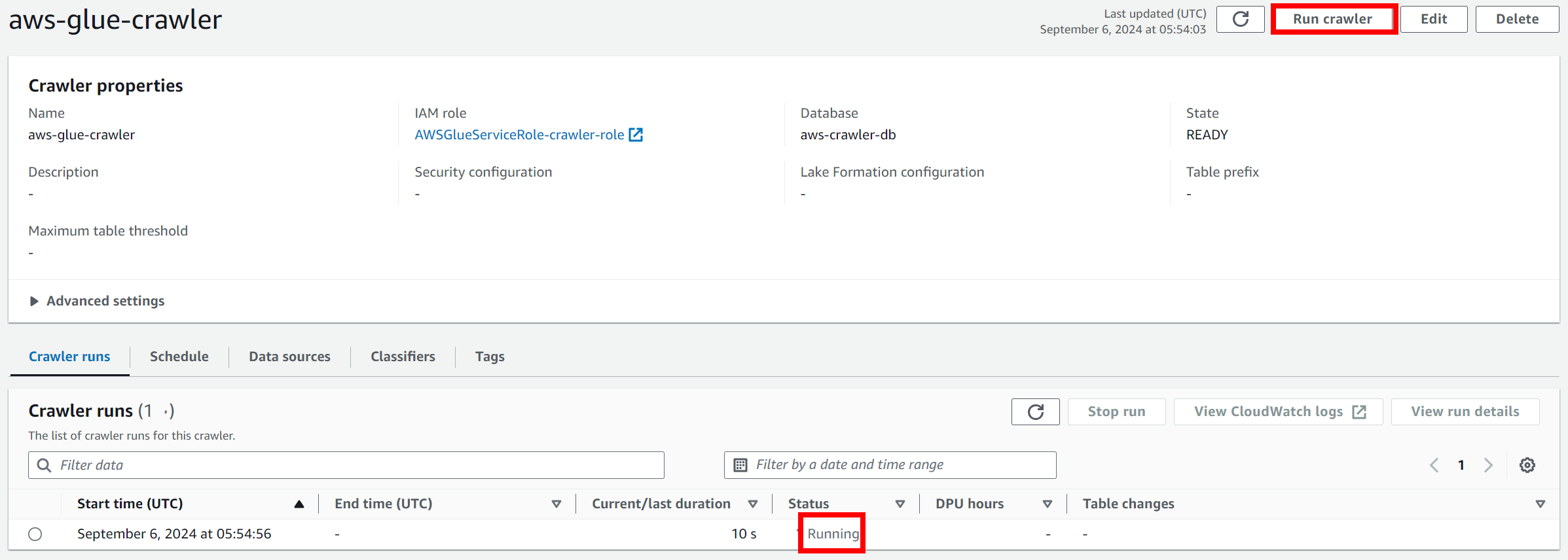
➜ AWS Glue > Crawlers > aws-glue-crawler > running
✅ AWS athena에서 쿼리 결과 확인

➜ 쿼리 편집
SELECT * FROM "aws-crawler-db"."inventory" inv
join "aws-crawler-db"."inventory_updated" inv_v
on inv.quality - inv_u_quality
** 참고 **
https://docs.aws.amazon.com/ko_kr/batch/latest/userguide/what-is-batch.html
AWS Batch란 무엇입니까? - AWS Batch
기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다. AWS Batch란 무엇입니까? AWS Batch를 사용하면 AWS 클라우드에서 배치 컴퓨팅 워
docs.aws.amazon.com
'AWS' 카테고리의 다른 글
| [ 4 ] (0) | 2024.09.13 |
|---|---|
| [ 3 ] (0) | 2024.09.12 |
| [ 2 ] (0) | 2024.09.11 |
| [ 1 ] - 기본 Setting (0) | 2024.09.10 |
| [ AWS Architecture Diagram ] (0) | 2024.09.05 |